Why is this doc so ugly ?
The year is 2025 and we are still producing this kind of documentation, with a light team only, no animations and no fancy stuff ? Well... The answer is Yes !
When I first introduced the libmodulor documentation in early 2025, I made a big mistake.
I thought I had to produce the same kind of "standard" documentation : the usual dark layout "à la shadcn, vercel, linear". The target of the lib is developers, and that's what they like after all ?
So that's why I used Fumadocs. I have been able to achieve the desired result very quickly and get something working "with less effort" as they say.
But I quickly had a problem : I didn't like the end result.
Don't get me wrong. The maintainer is doing a really great job and I'm not criticizing his work whatsoever. It's just not for me for a couple of reasons that I'll describe below.
No soul, no poetry
When you visit any developer oriented website nowadays, aren't you tired of this dark theme "à la shadcn, vercel, linear" ? I am.
I'm currently reading Rework (the book) and I stumbled upon this quote that was perfect for my situation :
Nobody likes plastic flowers. Pare down to the essence, but don't remove the poetry. Keep things clean and unencumbered but don't sterilize. It's a beautiful way to put it: Leave the poetry in what you make. When something becomes too polished, it loses its soul. It seems robotic.
@dhh or @jasonfried
And that's exactly what I feel when I land on this kind of website : soulless and robotic.
I'm not saying my layout and style are better. They are probably not for most people.
But since libmodulor is a passion project, I'd rather expose it the way I like.
And the way I like, is the good old way.
Build performance
This is a more serious one. Fumadocs is based on Next.js, so it comes with its problems. And the first one is build performance which affects a lot the DX.
Below is the output of the production build command.
➜ pnpm build
▲ Next.js 15.3.4
Creating an optimized production build ...
[MDX] updated map file in 359.02758300000005ms
✓ Compiled successfully in 19.0s # <==================== 😱😱😱😱😱😱😱😱😱😱😱😱😱😱😱😱😱😱😱😱
✓ Linting and checking validity of types
✓ Collecting page data
✓ Generating static pages (27/27)
✓ Collecting build traces
✓ Finalizing page optimization
Route (app) Size First Load JS
┌ ○ / 177 B 110 kB
├ ○ /_not-found 984 B 108 kB
├ ƒ /api/search 831 B 175 kB
├ ● /docs/[[...slug]] 9.04 kB 186 kB
├ ├ /docs
├ ├ /docs/concepts/architecture
├ ├ /docs/concepts/dependency-injection
├ └ [+17 more paths]
├ ○ /llms.txt 143 B 107 kB
└ ○ /sitemap.xml 143 B 107 kB
+ First Load JS shared by all 107 kB
├ chunks/191947cd-12454eddb1491ba9.js 53.2 kB
├ chunks/2084-ec78e9c98c6fcc4e.js 46.9 kB
└ other shared chunks (total) 6.79 kB
○ (Static) prerendered as static content
● (SSG) prerendered as static HTML (uses generateStaticParams)
ƒ (Dynamic) server-rendered on demandIt takes 19.0s to freshly build 27 pages on a very recent MacBook Pro M4.
And the same goes in "dev" mode. Each page visit takes forever to load if it hasn't been visited before.
I can't understand more the jokes about introducing react-router in a Next.js app.
More seriously, all of this is unacceptable and we must stop praising this framework. I really think it had its time. It was really great a couple of years ago, but this time is over. Next.js is the new Struts.
Runtime performance
Build performance is one thing but runtime is another one that clearly impacts the end users and the budget.
I shouldn't need a powerful server to run a documentation website.
Especially when I barely have 100 visitors per day.
So that's why I opted for a nano instance on Clever Cloud.
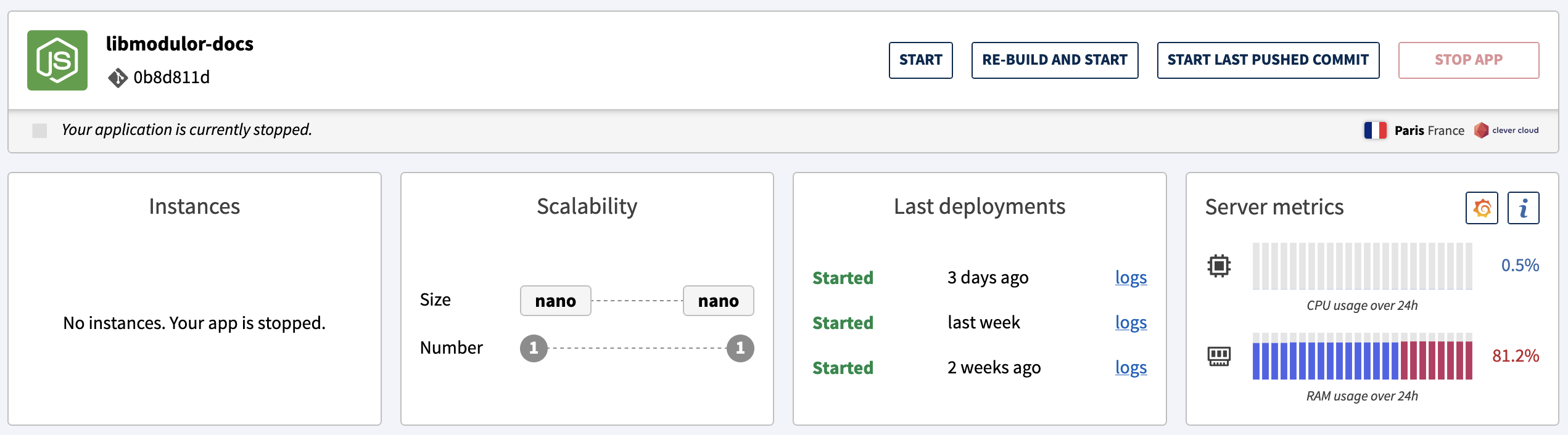
For whatever reason, the server RAM would suddenly become overloaded. To be honest, I don't want to deal with memory leaks (or simply high consumption) in other people's code, especially when they are "merchants of complexity".
I was just serving static pages so what the h*** ? Here again, we must stop praising this and go back to minimal server requirements to run simple things.
SEO performance
This is another big issue. I have absolutely no clue why, but the libmodulor documentation has never been fully indexed by Google.
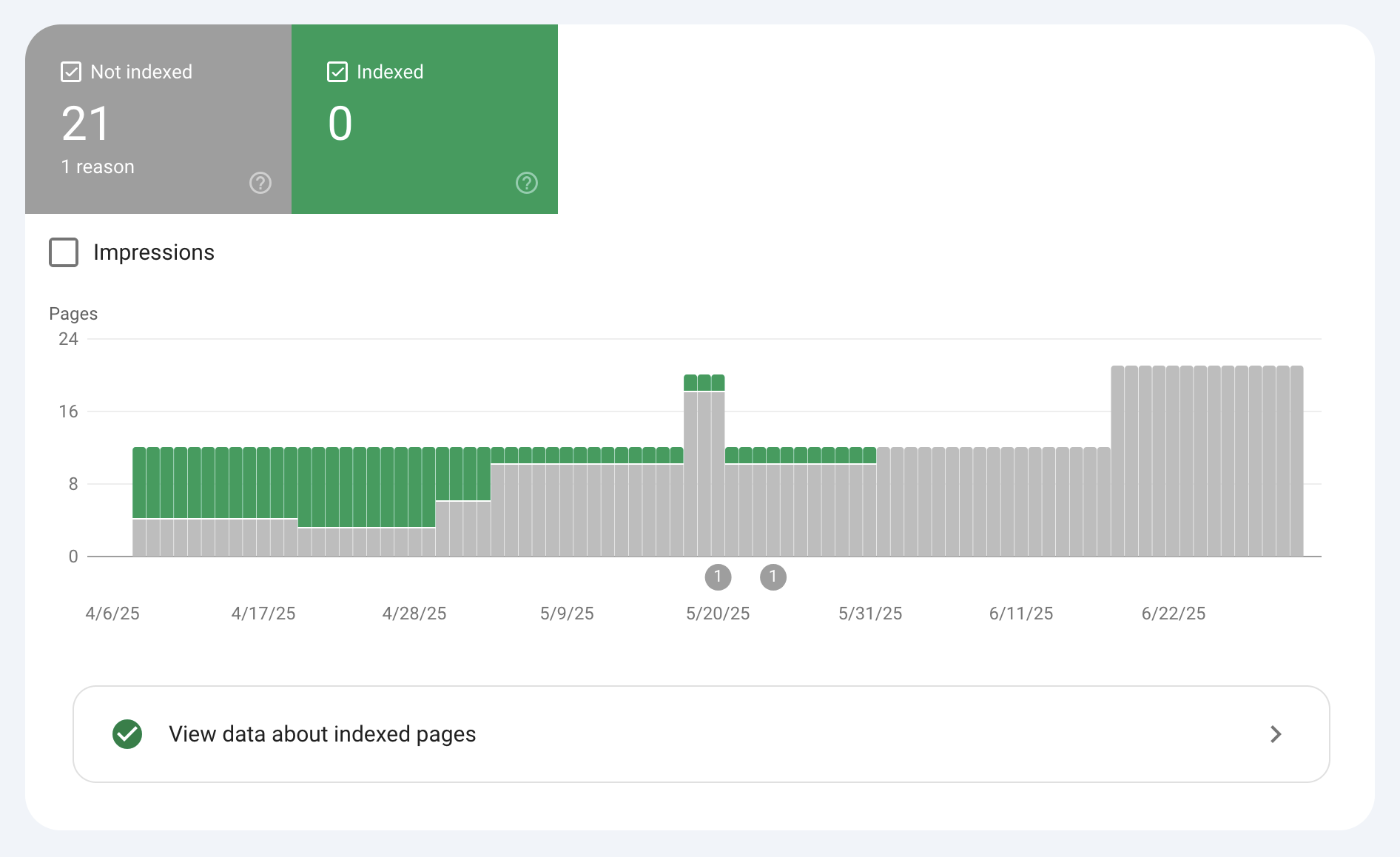
The Google Search Console is probably the worst tool produced by Google so I don't know what is wrong. Sometimes I got an error indicating that there was a "Temporary access error". Are the RAM spikes triggered by the GoogleBot ? Maybe.
In any case, if I hadn't changed anything, there is a good chance the chart would have kept its grey color. Hopefully it will turn green with this new version.
Note that during the port, I kept the URLs exactly identical since Google had already identified the pages.
Complexity
Whenever I'm starting to browse GitHub issues to achieve something very common, it's a good indicator that the tool is not for me. Especially when the tool solves 99 problems, 10 of them being mine, while not solving my other 25 problems.
I don't want workarounds. I don't want to pnpm add next-js-patch-whatever-is-wrong...
I investigated other solutions like Astro and Docusaurus but just by reading their GitHub issues I realized that they were the same.
This GitHub comment summarizes it better than I would.
Why do we have to do all this nonsense? Moreover, the problem is not fixed! It is a disaster to produce patch solutions without knowing what the problem is.
As I always say, I prefer to deal with my own complexity rather than someone else's.
The Solution
So I just decided to build my own. It's not perfect, it does not make coffee, tea and orange juice neither. But at least it does what I want it to do, I can change whatever I want, it looks the way I like it... And most of all, it builds and runs fast !
It's just plain old TypeScript producing plain old HTML files served by a plain old nginx server.
I just write content, run ./build.sh and open the HTML file in my browser using the file:// protocol.
There is no SSR, HMR, SST, TTZ, SMB, SPE or whatever.
There is a very simple hydration mechanism using directly the React primitives to load the use cases client side (e.g. examples => Standalone).
I auto-generate some pages directly from the library source tree (e.g. references => data types).
And so on...
In the end, I have a unique build.ts script that I run with bun. There is no magic.
Creating out path
Building components imports
Loading tree
Loading blocks
Loading pages
Building TOC
Loading layout
Building pages
Building sitemap
Building robots.txt
Copying images
Building mermaid diagrams
Generating single mermaid chart
Copying styles
Building hydratables
Done in 7s !7s is still a lot according to me.
Currently, most of the exec time is taken by playwright generating the Mermaid diagrams (it starts a headless Chrome everytime).
But there are other parts that I can optimize. For instance, instead of browsing the file tree twice, I can load the tree and the pages in a unique data structure only once. I can also parallelize steps than can be, especially the assets ones.
To release ?
./build-prod.sh
./release.sh
Copying files to server...Takes 1s and no need to restart anything.
All in all, I had fun building it and I'll have fun optimizing it.
And I have lots of funny ideas (nginx as a search engine using lua ? client side embedded search ? auto-generation of opengraph images, etc.).
As passionate developers, we should always keep this in mind instead of always rushing producing flavorless code with AI or using off-the-shelf tools that are not necessarily better, although they are built by very clever software engineers.